Test Data Management Model – Case Study for an EU Bank
Home
Case Studies
Test Data Management Model – Case Study for an EU Bank
Defining Test Data Management Goals for the Bank:
Optimized effort of QA
Enhanced offshoring
Other Factors For Defining Test Data Management Goals for the Bank:
No centralized process set for test data management for test execution
Each tester navigates through the available data set to find relevant test data resulting in more effort and time
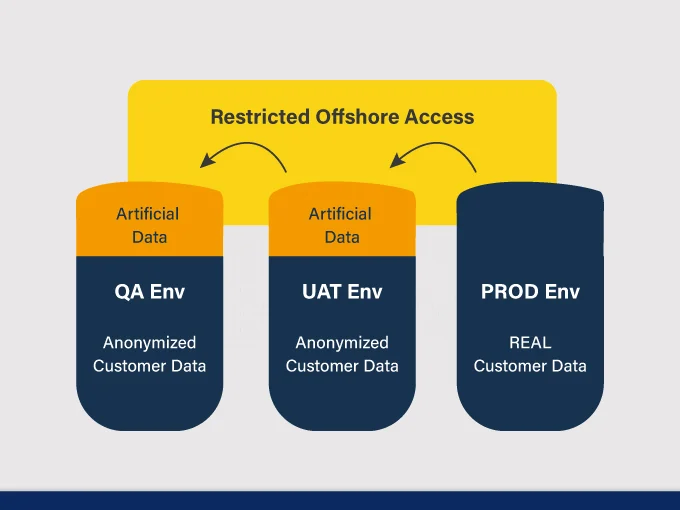
No ownership to ensure that offshore has access only to Artificial Data
Huge efforts spend on identifying and creating test data for every release after the test environment rebuilt
Solution Approach
Two-Stage Test Data Creation Process
1. Anonymization of Production Data
Data anonymization is done while maintaining referential integrity
Anonymization rules ensure that the business scenarios/rules for each data are unaffected
For e.g. age, location, account values are not disturbed, while DOB, address account numbers are anonymized
Trivialization, use of common names, exchange A->B, Same set rules, etc.
Tools used for Anonymization
Data Copy by DBA
PL/SQL Stored Procedures for Oracle DB
Python Based Scripts
Banks prefer not to use other industry-standard tools – For security reasons – As using other tools need more schema knowledge, while this method is one time copy of all data
Goals of Test data management team:
To provide timely test data support to all the testing groups
Restore the system (Test Data) to its original state after every Test environment re-built
Create more artificial test data to improve the offshoring ratio
To ensure offshore has access to ONLY artificial data
Define processes that will help maintain huge sets of test data
Create test data for new modules and maintain an existing test data set
2. Creation of Artificial Data
Selective test data created by QA team in UAT env and copied to QA env
Completely artificial users created covering all key scenarios
Application-specific data creation done
Requires more knowledge of schema, workflows, and business rules
This data is accessible for offshore testing
Tools used for artificial data creation
Created directly via UI through simple automated scripts in JAVA/Selenium
Standard industry tools can also be used depending on the tech stack and tools used in the org.
Data Optimization and Enrichment
Maintaining and retrieving the created data efficiently is a challenge
The dynamic nature of multiple applications requires different test data
Optimizing common data user requirements across applications to optimize and eliminate excess artificial users is done
Every new requirement verified against existing data set to reuse with modification of rights and roles as needed